
def solution(s):
length = len(s)
mid = length // 2
if length %2 == 0:
return s[mid-1:mid+1]
else:
return s[mid]
데이터 분리
과대적합
데이터를 너무 과도하게 학습한 나머지 해당 문제만 잘 맞추고 새로운 데이터를 제대로 예측 혹은 분류하지 못하는 현상
과적합 원인
- 모델의 복잡도
- 데이터 양이 충분하지 않음
- 학습 반복이 많음(딥러닝의 경우)
- 데이터 불균형(정상환자 - 암환자의 비율이 95: 5)
해결 - 테스트 데이터의 분리
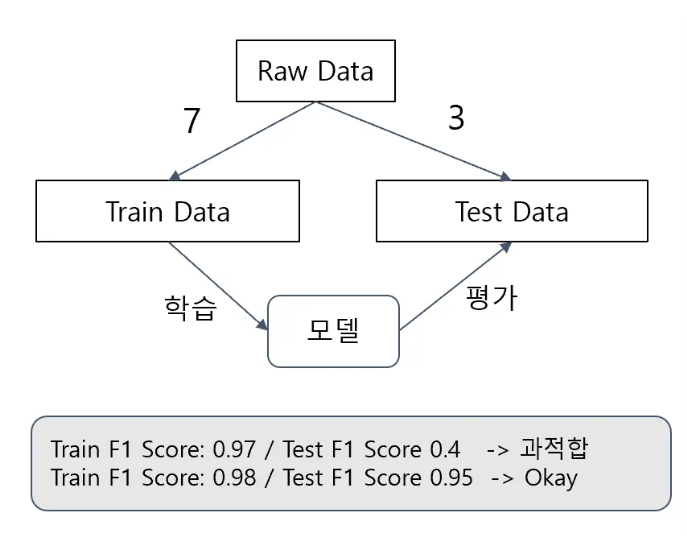
- 학습 데이터(Train Data): 모델을 학습(fit)하기 위한 데이터
- 테스트 데이터(Test Data): 모델을 평가 하기 위한 데이터
- 함수 및 파라미터 설명
- sklearn.model_selection.train_test_split
- 파라미터
- test_size: 테스트 데이터 세트 크기
- train_size: 학습 데이터 세트 크기
- shuffle: 데이터 분리 시 섞기
- random_state: 호출할 때마다 동일한 학습/테스트 데이터를 생성하기 위한 난수 값. 수행할 때 마다 동일한 데이터 세트로 분리하기 위해 숫자를 고정 시켜야 함
- 반환 값(순서 중요)
- X_train, X_test, y_train, y_test
- 파라미터
- sklearn.model_selection.train_test_split
교차 검증
데이터 셋을 여러 개의 하위 집합으로 나누어 돌아가면서 검증 데이터로 사용하는 방법
- K-Fold Validation
- 정의: Train Data를 K개의 하위 집합으로 나누어 모델을 학습시키고 모델을 최적화 하는 방법
- 이때 K는 분할의 갯수
- Split 1: 학습용(Fold 2~5), 검증용(Fold1)
- Split 2: 학습용(Fold1, 3~5), 검증용(Fold2)
- Split 5까지 반복 후 최종 평가
특징
- 데이터가 부족할 경우 유용함
- 함수
- skelarn.model_selection.KFold
- sklearn.model_selection.StrifiedKFold: 불균형한 레이블(Y)를 가지고 있을 때 사용
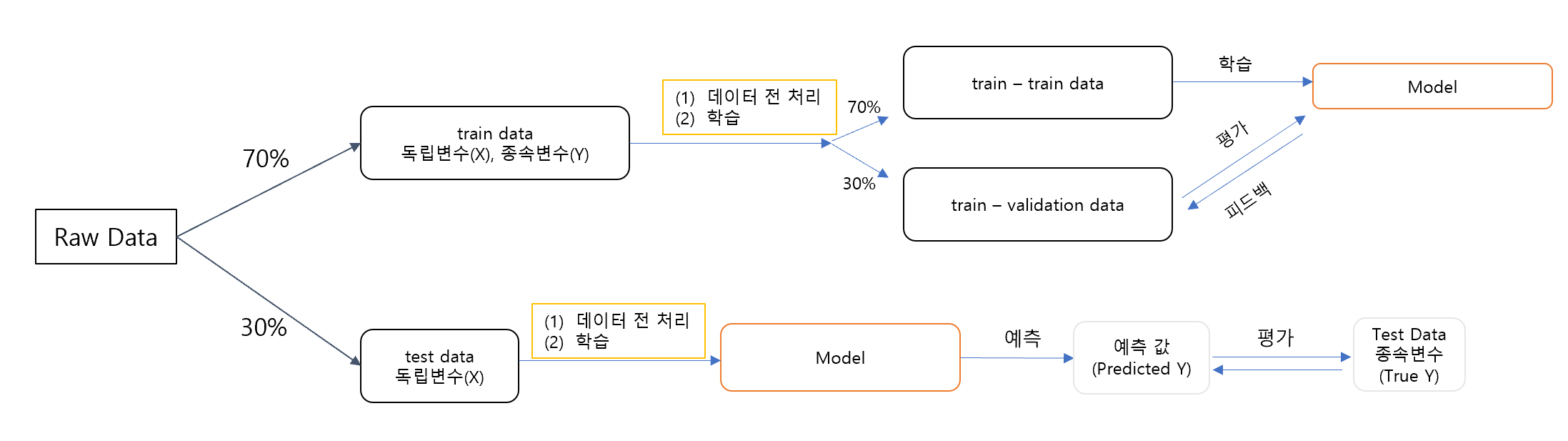
데이터 분석 프로세스
'TIL' 카테고리의 다른 글
| 심화 프로젝트 3일차 (1) | 2025.02.06 |
|---|---|
| 심화 프로젝트 2일차 (0) | 2025.02.05 |
| TIL - 코드카타, 머신러닝 심화(~1-7) (0) | 2025.01.24 |
| TIL - 코드카타, 머신러닝 기초 (0) | 2025.01.23 |
| TIL - 코드카타, 머신러닝 기초(~1-12) (0) | 2025.01.22 |