
내 풀이
def solution(phone_number):
length = len(phone_number)
phone = '*' * (length - 4)
number = phone_number[-4:]
return phone+number
리스트 컴프리헨션 이용
def hide_numbers(s):
return "*"*(len(s)-4)+s[-4:]
print("결과 : " + hide_numbers('01033334444'));
선형회귀 적용
파이썬 라이브러리
- scikit-learn: Python 머신러닝 라이브러리
- numpy: Python 고성능 수치 계산을 위한 라이브러리
- pandas: 테이블 형 데이터를 다룰 수 있는 라이브러리
- matplotlib: 대표적인 시각화 라이브러리, 그래프가 단순하고 설정 작업 많음
- seaborn: matplot기반의 고급 시각화 라이브러리, 상위 수준의 인터페이스를 제공
자주 쓰는 함수
- sklearn.linear_model.LinearRegression : 선형회귀 모델 클래스
- coef_: 회귀 계수
- intercept: 편향(bias)
- fit: 데이터 학습
- predict: 데이터 예측
- tips로 실습
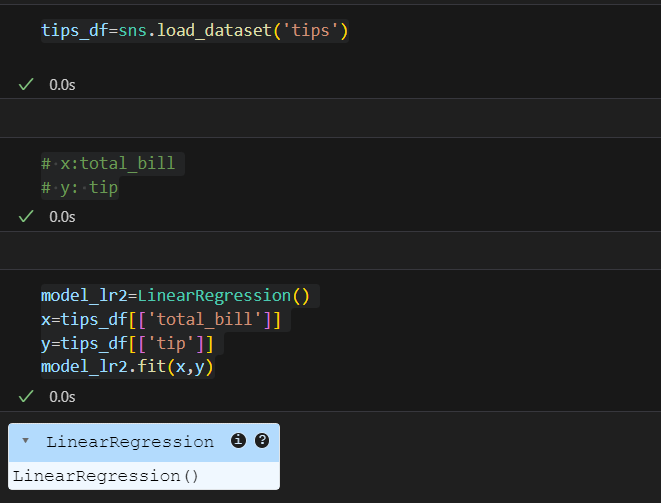

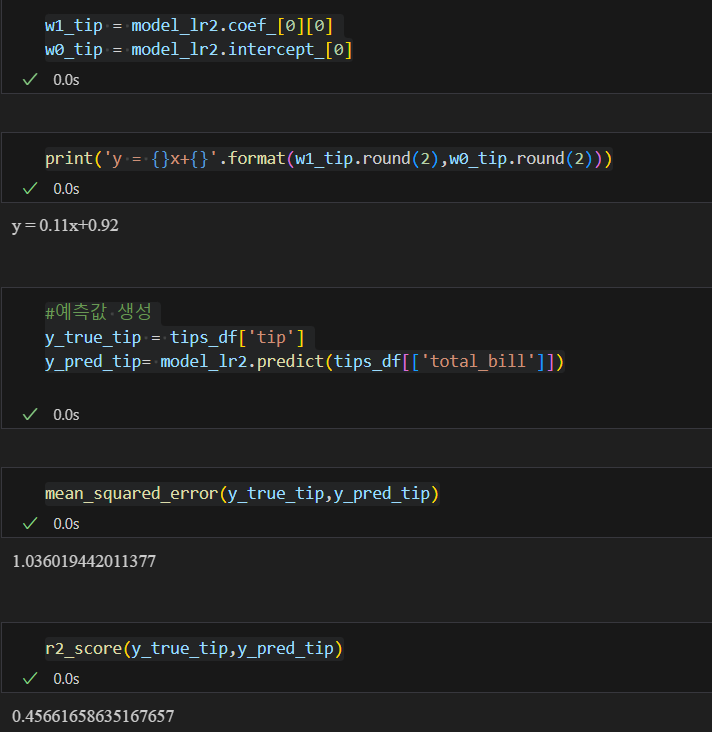

다중선형회귀

수치형 데이터
1. 연속형 : 두 개의 값이 무한한 개수로 나누어진 데이터
예) 키,몸무게
2. 이산형 : 두 개의 값이 유한한 개수로 나누어진 데이터
예) 주사위 눈, 나이
범주형 데이터
1. 순서형 자료: 자료의 순서 의미가 있음
예) 학점,등급
2. 명목형 자료: 자료의 순서 의미가 없음
예) 혈액형,성별
선형회귀 가정
1. 선형성: 종속 변수(Y)와 독립 변수(X) 간에 선형 관계가 존재해야 함
2. 등분산성: 오차의 분산이 모든 수준의 독립 변수에 대해 일정해야 함
3. 정규성: 오차 항은 정규 분포를 따라야 함
4. 독립성: X변수는 서로 독립적이어야 함
- 다중공산성 문제: 회귀분석에서 독립변수 간의 강한 상관관계가 나타나는 것
- 해결방법: 서로 상관관계가 높은 변수 중 하나만 선택, 두 변수를 차원축소해 1개로 축소
선형회귀 장점
- 직관적이며 이해하기 쉽고 X-Y관계를 정량화 할 수 있음
- 모델이 빠르게 학습됨 ( 가중치 계산이 빠름)
선형회귀 단점
- X-Y간의 선형성 가정이 필요함
- 평가지표가 평균포함 하기에 이상치에 민감함
- 범주형 변수를 인코딩시 정보 손실이 일어남
데이터 프로세스 개요
데이터 수집 > 전처리 > EDA > 모델링&평가 > 배포
'TIL' 카테고리의 다른 글
| TIL - 코드카타, 머신러닝 심화(~1-7) (0) | 2025.01.24 |
|---|---|
| TIL - 코드카타, 머신러닝 기초 (0) | 2025.01.23 |
| TIL - 코드카타, 머신러닝 기초 (~1-7) (0) | 2025.01.21 |
| TIL - 통계학 기초 (5,6주차) (0) | 2025.01.20 |
| TIL - 코드카타, 통계학 기초 (3,4주차) (0) | 2025.01.17 |