선형회귀
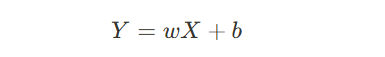
- w: 가중치
- b: 편향(Bias)
평가지표
MSE
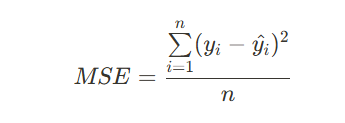
RMSE

R Square
전체 모형에서 회귀선으로 설명할 수 있는 정도

라이브러리
- scikit-learn: Python 머신러닝 라이브러리
- numpy: Python 고성능 수치 계산을 위한 라이브러리
- pandas: 테이블 형 데이터를 다룰 수 있는 라이브러리
- matplotlib: 대표적인 시각화 라이브러리, 그래프가 단순하고 설정 작업 많음
- seaborn: matplot기반의 고급 시각화 라이브러리, 상위 수준의 인터페이스를 제공
함수
- sklearn.linear_model.LinearRegression : 선형회귀 모델 클래스
- coef_: 회귀 계수
- intercept: 편향(bias)
- fit: 데이터 학습
- predict: 데이터 예측
다중선형회귀
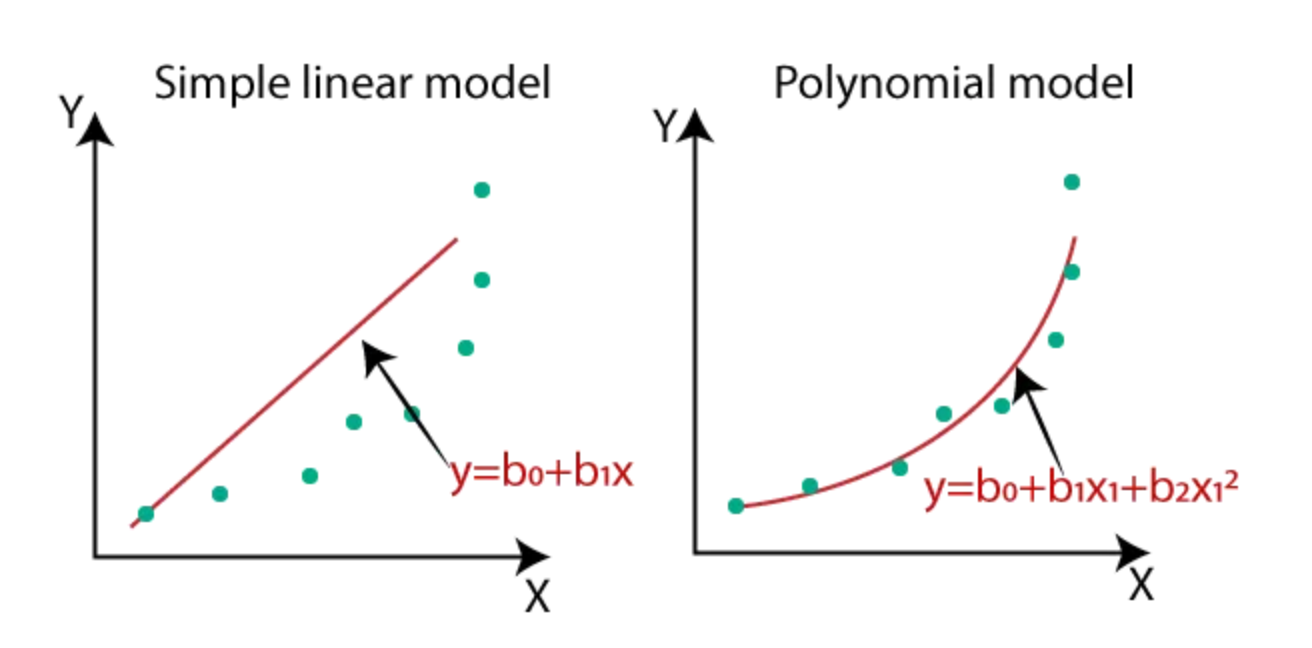
범주형 데이터는 인코딩 과정을 거쳐야함
선형회귀 가정
1. 선형성: 종속 변수(Y)와 독립 변수(X) 간에 선형 관계가 존재해야 함
2. 등분산성: 오차의 분산이 모든 수준의 독립 변수에 대해 일정해야 함
3. 정규성: 오차항은 정규분포를 따라야 함
4. 독립성: X변수는 서로 독립적이어야함
다중공선성
독립변수간의 강한 상관관계가 나타나는 것
해결방법
- 서로 상관관계가 높은 변수 중 하나만 선택(산점도 혹은 상관관계 행렬)
- 두 변수를 동시에 설명하는 차원축소(PCA) 실행하여 변수 1개로 축소
로지스틱 회귀
y가 0,1 범주형인 경우 적합


>> 로짓의 그래프가 더 선형적인 그림을 나타내서 기본식을 활용할 수 있게 됨
분류 평가 지표

정밀도 : 모델이 양성으로 예측한 결과 중 실제 양성의 비율

재현율: 실제 값이 양성인 데이터 중 모델이 양성으로 예측한 비율
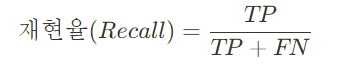
f1-Score: 정밀도와 재현율의 조화 평균

함수
- sklearn.linear_model.LogisticRegression : 로지스틱회귀 모델 클래스
- 속성
- classes_: 클래스(Y)의 종류
- n_features_in_ : 들어간 독립변수(X) 개수
- feature_names_in_: 들어간 독립변수(X)의 이름
- coef_: 가중치
- intercept_: 바이어스
- 메소드
- fit: 데이터 학습
- predict: 데이터 예측
- predict_proba: 데이터가 Y = 1일 확률을 예측
- 속성
- sklearn.metrics.accuracy: 정확도
- sklearn.metrics.f1_socre: f1_score
'TIL' 카테고리의 다른 글
| TIL - 코드카타 (0) | 2025.02.20 |
|---|---|
| TIL - 코드카타 (0) | 2025.02.19 |
| TIL - SQL (5주차) (0) | 2025.02.17 |
| TIL - 태블로 (3,4주차) (0) | 2025.02.17 |
| TIL - 태블로 (1,2주차) (0) | 2025.02.13 |