코드카타
24.

def solution(seoul):
for i in range(len(seoul)):
if seoul[i] == 'Kim':
return "김서방은 " + str(i) + "에 있다"
[1주차]
통계가 중요한 이유?
- 데이터를 요약하고 패턴 발견
- 추론을 통해 결론을 도출화할 수 있음
- 데이터 기반의 의사결정을 내릴 수 있음
- 기업이 현명한 결정을 내리고 수익을 창출하기 위해 필요함
기술통계
- 평균, 중앙값,분산,표준편차 사용
- 데이터를 특정 대표값으로 요약
- 데이터에 대한 대략적인 특징을 간단하고 쉽게 알 수 있음
- 예외가 존재할 수 있고 모든 부분을 확인할 수는 없음
중앙값?
- 데이터를 크기 순서대로 정렬했을 때 중앙에 위치한 값
분산?
- 데이터 값들이 평균으로부터 얼마나 떨어져 있는지를 나타내는 척도
- 분산이 크면 데이터가 넓게 퍼져 있고, 작으면 평균에 가까움
- 데이터 값에서 평균을 뺸 값을 제곱한 후 모두 더하고 데이터의 개수로 나눔
표준편차?
- 분산의 제곱근을 취해 계산
추론통계
- 신뢰구간, 가설검정 사용
- 데이터의 일부를 가지고 전체를 추정함
신뢰구간?
- 모집단의 평균이 특정 범위 내에 있을 것이라는 확률
- 일반적으로 95% 신뢰구간이 사용
가설검정?
- 모집단에 대한 가설을 검증하기 위해 사용
- 귀무가설: 검증하고자 하는 가설이 틀렸음을 나타내는 기본 가설
- 대립가설: 반대 가설로 주장하는 바를 나타냄
다양한 분석 방법
1) 위치추정
데이터를 중심을 확인하려면?
- 평균, 중앙값이 대표적인 위치 추정 방법
# 이 data는 아래에서도 계속 사용 됩니다
data = [85, 90, 78, 92, 88, 76, 95, 89, 84, 91]
mean = np.mean(data)
median = np.median(data)
print(f"평균: {mean}, 중앙값: {median}")
2) 변이추정
데이터들이 얼마나 다른지 확인하려면?
- 분산, 표준편차, 범위 등을 사용
범위
- 가장 큰 값과 작은 값의 차이를 나타내는 간단한 분포의 측도
- 데이터가 어느 정도의 변동성을 가지는지 쉽게 파악 가능
- 기본적인 데이터 분석에서 자주 사용됨
variance = np.var(data)
std_dev = np.std(data)
data_range = np.max(data) - np.min(data)
print(f"분산: {variance}, 표준편차: {std_dev}, 범위: {data_range}")
3) 데이터 분포 탐색
데이터 값들이 어떻게 이루어져있는지 확인하려면?
-히스토그램과 Box plot이 대표적인 방법
4) 이진 데이터와 범주 데이터 탐색
데이터들이 서로 얼마나 다른지 확인하는 방법?
- 개수가 가장 많은 값 주로 사용
- 파이그림과 막대 그래프
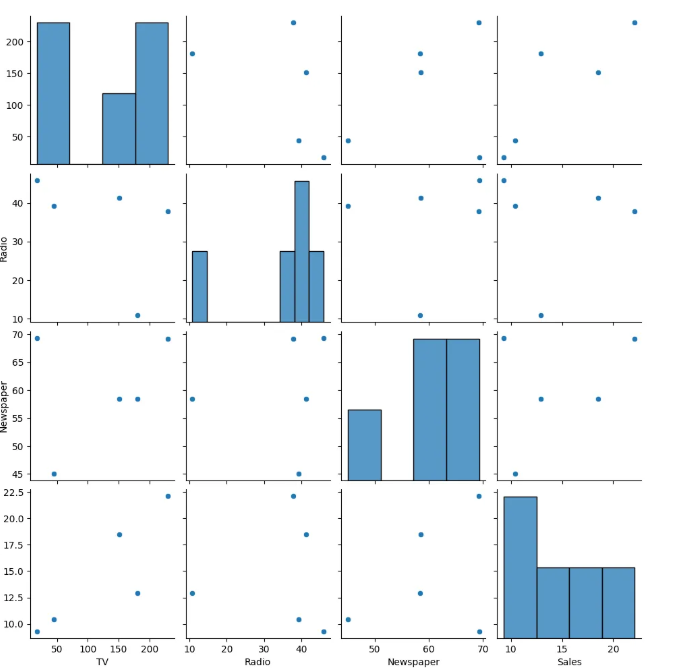
5) 상관관계
데이터들끼리 서로 관련 있는지 확인하는 방법
- 상관계수는 두 변수 간의 관계를 측정하는 방법
- -1이나 1에 가까워지면 강력한 상관관계를 가짐
- 0에 가까울 수록 상관관계 없음
6) 인과관계와 상관관계 차이
- 인과관계는 상관관계와 다르게 원인, 결과가 분명해야함
- 상관관계는 두 변수간의 관계를 나타내고, 인과관계는 한 변수가 다른 변수에 미치는 영향을 나타냄
7) 두 개 이상의 변수 탐색
다변량 분석 : 여러 변수간의 관계를 분석하는 방법
[2주차]
모집단
관심의 대상이 되는 전체 집단
표본모집단에서 추출한 일부
표본오차
- 표본에서 계산된 통계량과 모집단의 진짜 값 간의 차이
- 표본 크기가 클수록 표본 오차는 작아짐
- 무작위 추출 방법을 사용하면 줄일 수 있음
신뢰구간
- 모집단의 특정 파라미터에 대해 추정된 값이 포함될 것으로 기대되는 범위
- 신뢰구간 = 표본평균 +- z( 신뢰수준에 해당하는 값) x 표준오차
stats.t.interval 이란?
- scipy.stats는 SciPy 라이브러리의 일부로, 통계 분석을 위한 다양한 함수와 클래스들을 제공하는 모듈
- scipy.stats.t.interval 함수는 주어진 신뢰 수준에서 t-분포를 사용하여 신뢰 구간을 계산하는 데 사용
scipy.stats.t.interval(alpha, df, loc=0, scale=1)
alpha?
신뢰수준
95%를 원하면 0.95로 설정
df?
자유도
표본크기에서 1을 뺀 값으로 설정
loc?
위치로, 일반적인 표본 평균 설정
scale?
일반적으로 표본 표준 오차를 설정
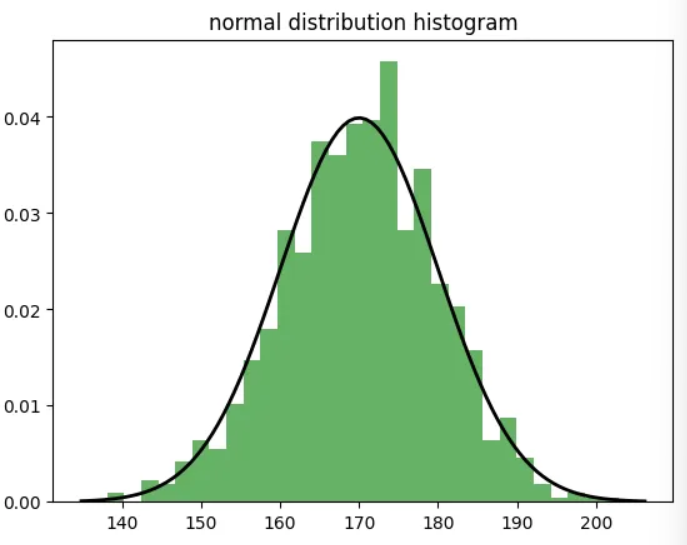
정규 분포
- 정규분포는 종 모양의 대칭 분포로, 대부분의 데이터가 평균 주위에 몰려 있는 분포
- 평균을 중심으로 좌우 대칭이며, 평균에서 멀어질수록 데이터의 빈도가 감소
- 표준편차는 분포의 퍼짐 정도를 나타냄
긴 꼬리 분포
- 긴 꼬리 분포는 대부분의 데이터가 분포의 한쪽 끝에 몰려 있고, 반대쪽으로 긴 꼬리가 이어지는 형태의 분포
- 이는 정규분포와 달리 대칭적이지 않고 비대칭적
- 특정한 하나의 분포를 의미하지 않으며 여러 종류의 분포(예: 파레토 분포, 지프의 법칙, 멱함수)를 포함할 수 있음
일부가 전체적으로 큰 영향을 미치는 경우에 사용

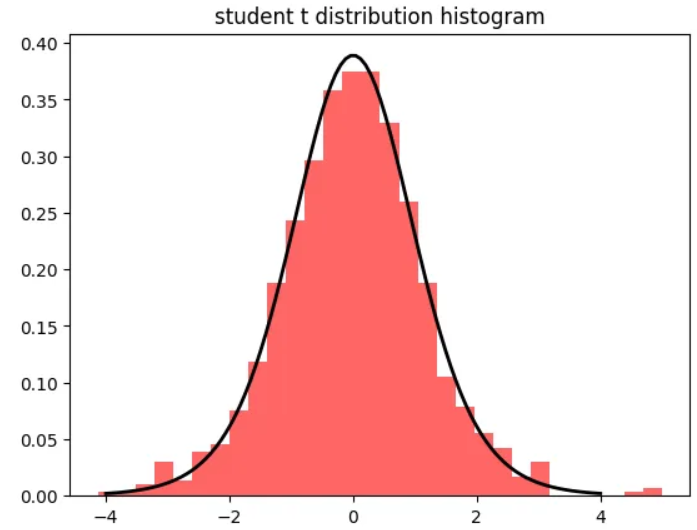
스튜던트 t 분포
- 데이터가 적은 경우 사용
- 표본 크기가 커지면 정규분포에 가까워짐
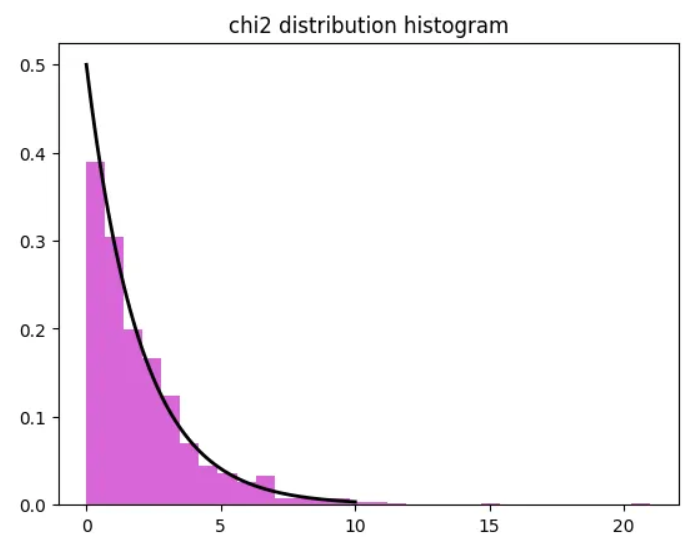
카이제곱분포
- 범주형 데이터의 독립성 검정이나 적합도 검정에 사용되는 분포
- 자유도에 따라 모양이 달라짐
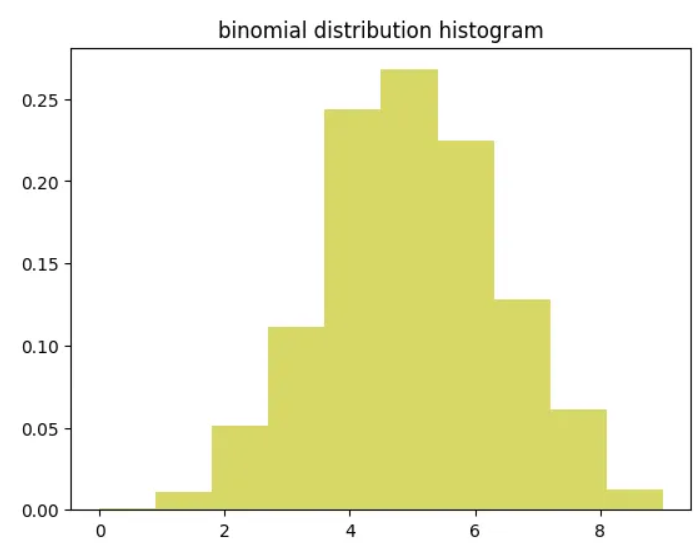
이항분포
- 결과가 2개 나오는 상황일 때 사용하는 분포
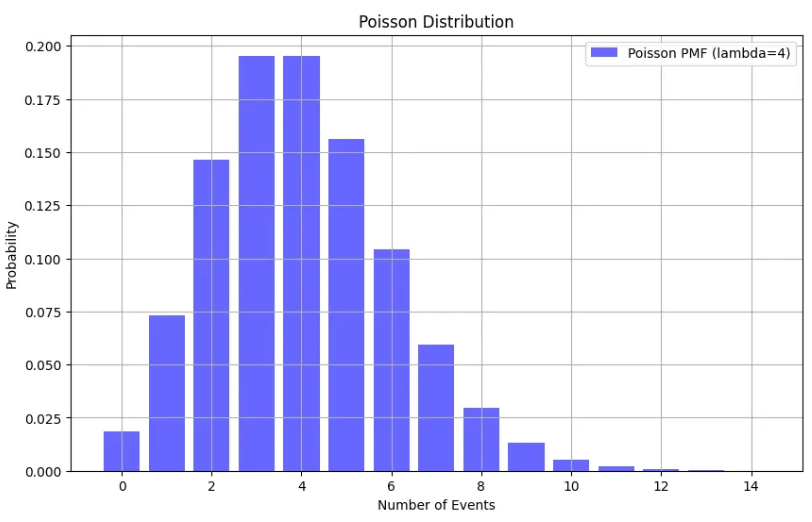
푸아송 분포
- 단위 시간 또는 단위 면적 당 발생하는 사건의 수를 모델링할 때 사용하는 분포
- 단위 시간 또는 단위 면적당 희귀하게 발생하는 사건의 수를 모델링하는 데 적합
'TIL' 카테고리의 다른 글
| TIL - 통계학 기초 (5,6주차) (0) | 2025.01.20 |
|---|---|
| TIL - 코드카타, 통계학 기초 (3,4주차) (0) | 2025.01.17 |
| TIL - SQL (4주차) (0) | 2025.01.15 |
| [1/14] TIL - 코드카타, 기초 프로젝트, SQL (2,3주차) (1) | 2025.01.14 |
| [1/7] TIL - SQL (1주차) (0) | 2025.01.07 |